Demystifying Hyperledger Fabric (2/3): Private Data Collection

Welcome to the 2nd article of Demystifying Hyperledger Fabric series. This article assumes that the reader has knowledge about Hyperledger Fabric architecture already. In case you have come across this article, I recommend you to check out the previous article first.
In the previous article, you have learned the essential architecture of Hyperledger Fabric. In this article, you will learn another key feature of the Fabric called Private Data Collection.
Prior to Fabric version 1.2, when a group of organizations needs to keep data private from other organizations joining the same channel, that subset of organizations has to create a new separate channel. This causes additional administrative overhead such as managing chaincodes, endorsement policies, membership service provider configurations, and etc. Moreover, separating a new channel could not handle the case that some organizations may need to keep a portion of data private but share the rest of the data with other organizations.
Private Data Collection was introduced in Hyperledger Fabric version 1.2. With this feature, data considered private can be configured to share with only authorized organizations whereas the public data can be shared with all organizations on a channel, without the need to create a separate channel. Moreover, this feature also keeps private data confidential from an ordering service, which may be controlled by an organization unauthorized to see the data.
The remaining of this article is organized as follows:
Overview of Private Data Collection
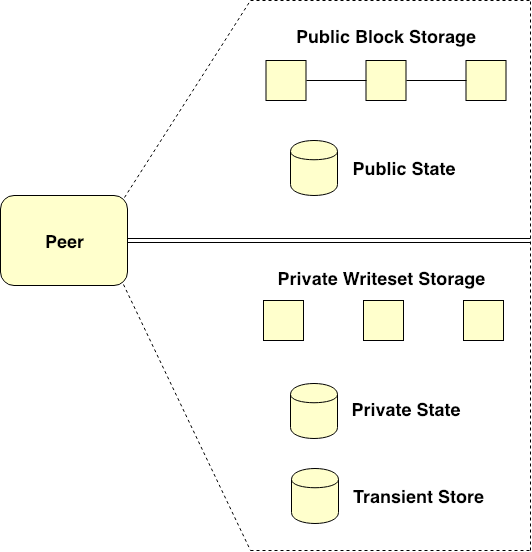
Figure 1. Peer’s ledger enabled for Private Data Collection use
Fabric Peer’s underlying ledger that is enabled for Private Data Collection use can be depicted in Figure 1. Typically, the Peer’s ledger with Private Data Collection enabled comprises two primitive parts as follow.
The first part is public data section which stores all public data and transactions for a particular channel. Public data section consists of two entities including Public Block Storage and Public State Database as shown in the upper section of Figure 1.
Specifically, Public Block Storage is a blockchain that holds the history of all public transactions for every chaincode instantiated on a channel. Public State Database is a world state storage which maintains the current state of public variables for a specific chaincode. For any particular channel, that is, the public data section contains only single Public Block Storage instance but the section can contain multiple Public State Database instances based on a number of chaincodes instantiated on a channel.
The second part is private data section which stores all private data and transactions for a specific channel. Private data section consists of three entities including Private Writeset Storage, Private State Database, and Transient Store Database as shown in the lower section of Figure 1.
Private Writeset Storage collects the history of all private transactions for a specific private data collection. Each Peer’s ledger can contain multiple Private Writeset Storage instances depending on a number of private collections configured for that specific Peer. Actually, this kind of storage is not a blockchain, but one kind of typical logging persistent database.
Private State Database is a world state storage which holds the current state of private variables for a specific private collection. Like the case of Private Writeset Storage, multiple Private State Database instances can be maintained by the Peer’s ledger relying on a number of private collections configured for that specific Peer.
The last entity in the private data section is Transient Store Database. This kind of storage is used as an impermanent database for temporarily storing Private Data during a transaction invocation process. More details on Transient Store Database will be explained later on.
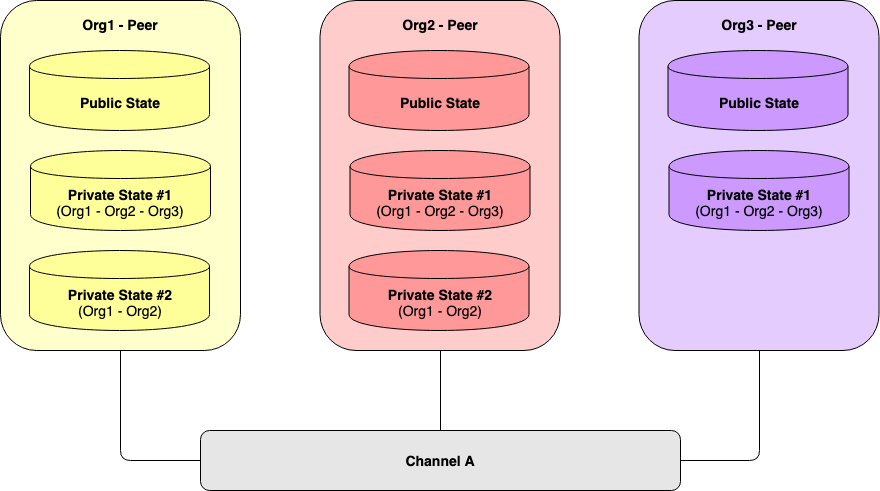
Figure 2. Peers maintaining multiple Private Data Collections
Any single chaincode can refer to multiple private data collections. Figure 2 illustrates three peers from different organizations referring to two collections of private data on the same channel. As you can see, all the three Peers maintain the Private State Database instance for the private collection no. 1. Meanwhile, the Private State Database instance for the private collection no. 2 is privately managed by Org1’s Peer and Org2’s Peer only.
Interestingly, Public State Database typically stores the current state of public variables for a specific chaincode. Anyway, this database also stores hashes of the modified private data sets associated with that specific chaincode. In other words, the hash of private data would be endorsed, ordered, and committed into the ledgers of every peer on the channel the same as the public data. The hash is used for state validation before updating the private data into the ledger of each authorized peer. The hash also serves as evidence of the transaction for audit purposes. More on this will be discussed later.
Even though the hash of private data would be stored publicly on a channel, no unauthorized peer can reverse the hash to the original contents.
|
|
The private data collections in Figure 2 can be translated into the config file as the code snippet above. This article would not get into the configuration details, however, just give you a concept of how private data collections can be configured. If you need to know more, please refer to this link.
Let’s focus on the collection property named policy. This property defines which organizations’ peers are allowed to persist the collection data. In other words, any private data collection would be stored on the authorized peers in accordance with this policy property. To keep private collections confidential from one another, furthermore, each peer will store different collections on separate Private State Database instances as well as on separate Private Writeset Storage instances.
Underlying Mechanism of Private Data Collection
This section discusses more details on the underlying mechanism of Private Data Collection.
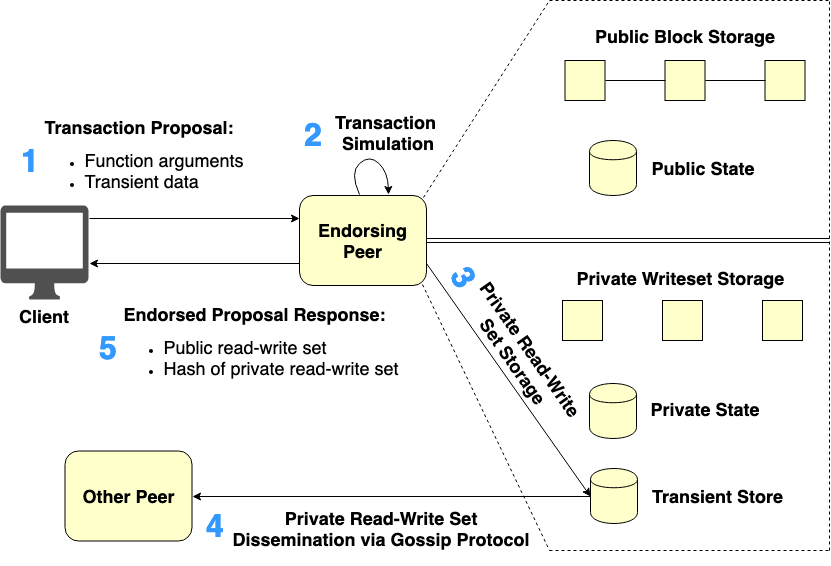
Figure 3. Endorsement phase of the transaction invocation with Private Data
Endorsement phase of the transaction invocation with Private Data can be described according to Figure 3. Like normal transaction proposals, the transaction proposal with Private Data will be generated at Client (Step 1 in Figure 3). The transaction proposal’s payload, however, would be composed of two parts including Function Arguments and Transient Data.
Function Arguments contain public chaincode function arguments like what normal transaction proposals do. Whereas, Transient Data contain private data arguments which would neither be transacted and stored into Public Block Storage nor Public State Database. In other words, there is no unauthorized peer would ever have access to private data.
The generated transaction proposal would then be submitted to the chosen Endorsing Peers in order to simulate and endorse it (Step 2 in Figure 3). After the transaction simulation process, a certain part of the simulation results called private read-write set containing the actual private simulation data would be temporarily stored into Transient Store Database inside each Endorsing Peer’s ledger (Step 3 in Figure 3).
Each Endorsing Peer, in turn, tries to disseminate the generated private read-write set via the gossip data dissemination protocol to at least n other collection member peers across authorized organizations (Step 4 in Figure 3) where n is a minimum number of member peers required the private data to be distributed to at the endorsement time (the value n is controlled by the property requiredPeerCount specified in the private data collection definition).
The above step is considered important for data redundancy purposes. If Endorsing Peer becomes unavailable during the transaction commit time, other peers that are collection members but did not yet receive the private read-write set at the endorsement time will be able to pull this private data from peers that the private data were disseminated to.
Endorsing Peer will endorse the proposal response if and only if it can successfully distribute the private read-write set to at least n other collection member peers. Next, the endorsed proposal response is sent back to Client (Step 5 in Figure 3). The endorsed proposal response would contain two parts of information, namely public read-write set and hash of private read-write set.
Public read-write set contains a change list of public variables related to the invoked transaction. Hash of private read-write set is a hash value of a modification list of the private variables that have previously been stored in Transient Store Database (Step 3 in Figure 3). The hash of private read-write set will be used for state validation before updating the private data into the ledger of each authorized peer. These two parts of the proposal response will get ordered, validated, and committed to Public Block Storage and Public State Database.
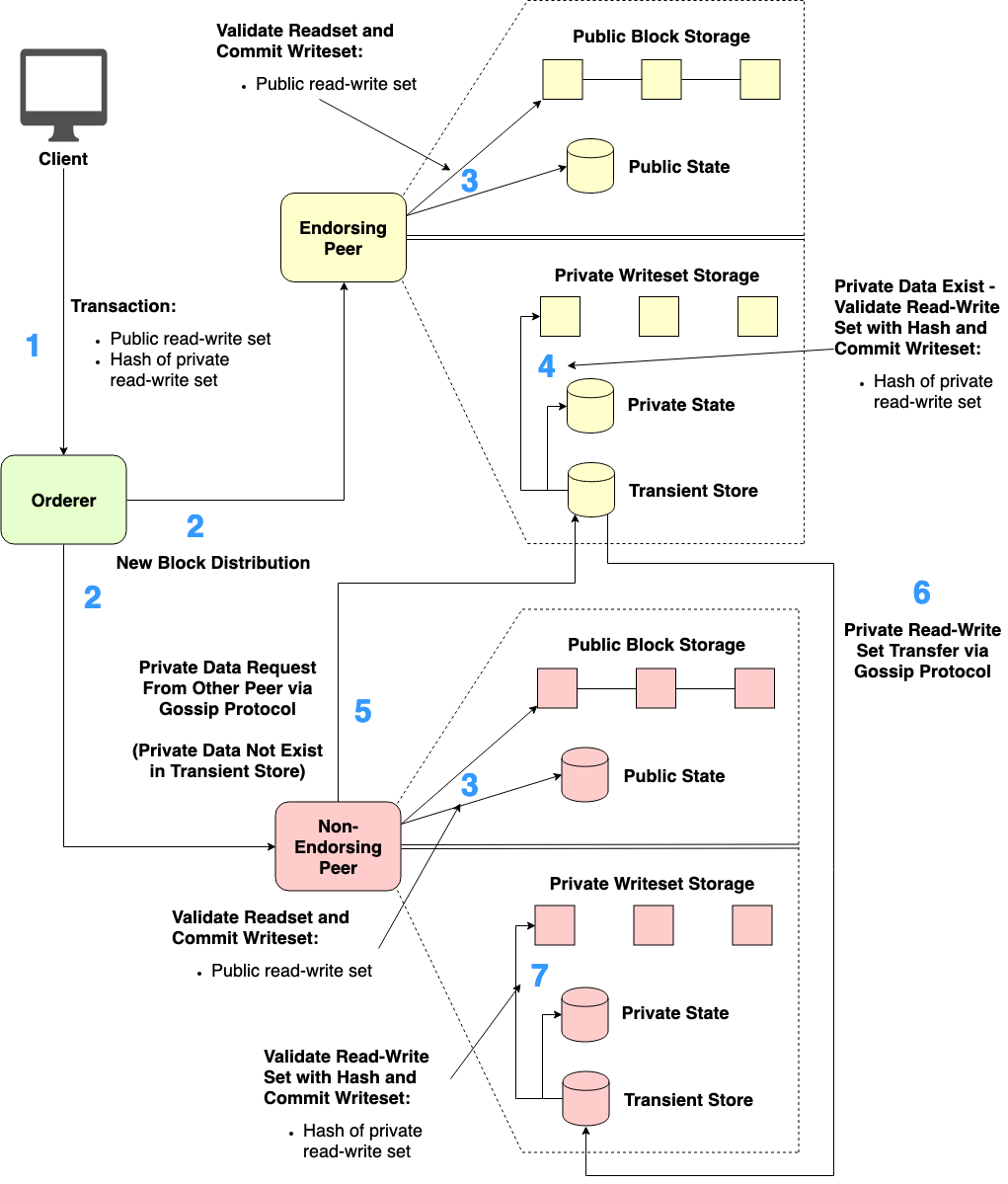
Figure 4. Ordering and validation-commitment phases of the transaction invocation with Private Data
Ordering and validation-commitment phases of the transaction invocation with Private Data can be described according to Figure 4. After the transaction proposal has been endorsed by Endorsing Peers, Client generates the transaction bundled with the set of endorsed proposal responses and then sends that transaction to Orderer (Step 1 in Figure 4).
Next, Orderer orders the received transactions (including other transactions), generates a new block of ordered transactions, and distributes the generated block to all Peers on the channel (Step 2 in Figure 4).
Then, each Peer processes each transaction in the received block one by one. That is, each Peer validates the public readset of the transaction against its local Public State Database and commits the public writeset of the transaction into its local Public Block Storage as well as updating the Public State Database (Step 3 in Figure 4).
Next, each Peer detects that the transaction being processed contains the hash of private read-write set. If any Peer discovers that it is a member authorized to see that exact private data collection, that Peer will use the hash value to verify the existence of the exact private read-write set stored in its Transient Store Database.
If the exact private read-write set exists in Transient Store Database, Peer will validate the private readset against its Private State Database and commit the private writeset into its Private Writeset Storage as well as updating the Private State Database. Finally, Peer removes the private read-write set from Transient Store Database (Step 4 in Figure 4).
In case there is any Peer which is a member of the exact private data collection but missing the exact private read-write set at the endorsement time, that Peer will send a pull request for the missing private read-write set to other member Peers through the gossip data dissemination protocol (Step 5 in Figure 4). The requested private read-write set would be transferred to the requesting Peer via the gossip protocol and temporarily store into its Transient Store Database (Step 6 in Figure 4).
Later, Peer in question will verify the received private read-write set with the corresponding hash. If the verification succeeds, Peer validates the received private readset against its Private State Database and commit the private writeset into its Private Writeset Storage. Peer also updates the Private State Database and eventually removes the private read-write set from Transient Store Database (Step 7 in Figure 4).
Transaction Invocation Workflow with Private Data
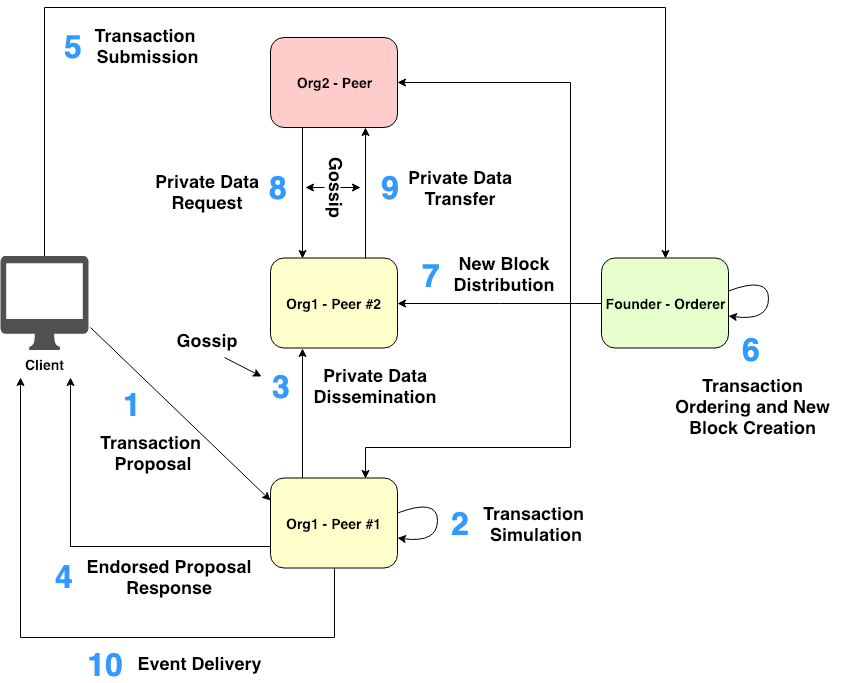
Figure 5. The invocation workflow of the transaction with Private Data
The step-by-step workflow of Fabric transaction invocation with Private Data is briefly summarized in Figure 5:
-
Client makes a transaction proposal including function arguments and transient data, signs the proposal with User’s certificate, and sends the transaction proposal to the set of pre-determined Endorsing Peers on a specific channel.
-
Each Endorsing Peer verifies User’s identity and authorization from the proposal payload. If the verification check passes, Endorsing Peer simulates the transaction. Private read-write set from the simulation results is stored into Transient Store Database inside the Peer’s ledger.
-
Each Endorsing Peer disseminates the private read-write set to other authorized Peers for data redundancy purposes via the gossip protocol.
-
Once a number of private data dissemination successes reach the minimum required count specified in the private data collection definition, Endorsing Peer generates the proposal response including the hash of the private read-write set. Then, Endorsing Peer endorses the generated response using its certificate and finally sends the generated response back to Client.
-
Client accumulates and checks the endorsed proposal responses from Endorsing Peers. Then, Client submits the transaction attached with the endorsed proposal responses to Orderer.
-
Orderer orders the received transactions, generates a new block of ordered transactions, and signs the generated block with its certificate.
-
Orderer broadcasts the generated block to all Peers on the relevant channel. Each Peer verifies the endorsement of each transaction in the received block against the invoked chaincode’s endorsement policy and then validates the public readset of each transaction against its Public State Database. If the validation check succeeds, the public writeset of each transaction is updated into every Peer’s Public State Database. The received block is also appended into every Peer’s Public Block Storage. Later, each authorized Peer verifies the private read-write set that is temporarily stored in its Transient Store Database (if exists) against the hash of private read-write set. Peer also validates the private readset against its Private State Database. If all the verification and validation processes succeed, the private writeset is updated into Peer’s Private State Database. The private writeset is also committed into Peer’s Private Writeset Storage. Finally, Peer removes the private read-write set from its Transient Store Database.
-
In case there is any authorized Peer missing the private read-write set during the endorsement time, that Peer will send a pull request for the missing private read-write set via the gossip protocol to other authorized Peers.
-
The missing private read-write set will be transferred from the requested Peer to the requesting Peer via the gossip protocol. Consequently, the received private read-write set will get verified and validated before committing into the Peer’s Private State Database and Private Writeset Storage (Similar to what happened in Step 7).
-
Client receives any subscribed events from EventHub service.
Private Data Purging
Private data can periodically get purged from peers. In the private data collection definition, there is a collection property called blockToLive which indicates how long the private data should live on the private database. Let’s say we set blockToLive to 50,000. The private data will be automatically purged from the private database if the data have not been modified for 50,000 blocks. If blockToLive was set to 0, the private data will be kept into the private database indefinitely. That is, the private data will never get purged. Refer to Private Data’s architecture reference for more info.
Even though the private data might be permanently removed from the private database, all hashes corresponding to the removed private data could not be removed as they were committed into Public Block Storage, which is a blockchain. Therefore, the hashes can be used as evidence of the transactions for audit purposes even if the original private data have vanished.
Summary
In this article, you have learned Private Data Collection, one of the key features of Hyperledger Fabric. Hope you understand how Hyperledger Fabric works better and feel free to leave your valuable comments or suggestions if you would like. Thanks for reading :)
In the next article which is the last article of the series, you will learn about network traffic handling, service discovery, and operations service in Hyperledger Fabric. See you again.
This series of articles is organized as follows:
-
Demystifying Hyperledger Fabric (1 / 3): Fabric Architecture
-
Demystifying Hyperledger Fabric (2 / 3): Private Data Collection