Demystifying Hyperledger Fabric (3/3): Network Traffic Handling, Service Discovery, and Operations Service

Welcome to the 3rd article which is the final article of Demystifying Hyperledger Fabric series. In the 1st article, the underlying architecture of Hyperledger Fabric has been explained. The 2nd article describes one of the important features of the Fabric called private data collection.
I would like to dedicate this article to discuss some of the facilitating supplementary services in Hyperledger Fabric including the following topics: Network Traffic Handling, Service Discovery, and Operations Service.
The remaining of this article is organized as follows:
Network Traffic Handling
Network traffic congestion might be one of the most potential issues on Fabric channel, due to multiple participating organizations joining the channel. Each organization, furthermore, can possess multiple peers. Let’s imagine if the number of participating organizations and related peers increases over time, Orderer would get overburdened with tasks in distributing blocks of transactions to every peer on every channel. As a result, Orderer is prone to be a single point of failure.
To provide Crash Fault Tolerance (CFT) to Orderer, Hyperledger Fabric currently supports two implementations of CFT ordering service namely Kafka and Raft. Furthermore, several types of Byzantine Fault Tolerant (BFT) ordering service are under development as well. Please refer to this link for more info.
In addition to mitigating the block distribution overhead of Orderer, Leading Peers were introduced to all participating organizations. Each organization can selectively entitle which peers to be Leading Peers. As shown in Figure 1 below, Org1’s Peer no. 2 and Org2’s Peer no. 2 are designated to be Leading Peers.
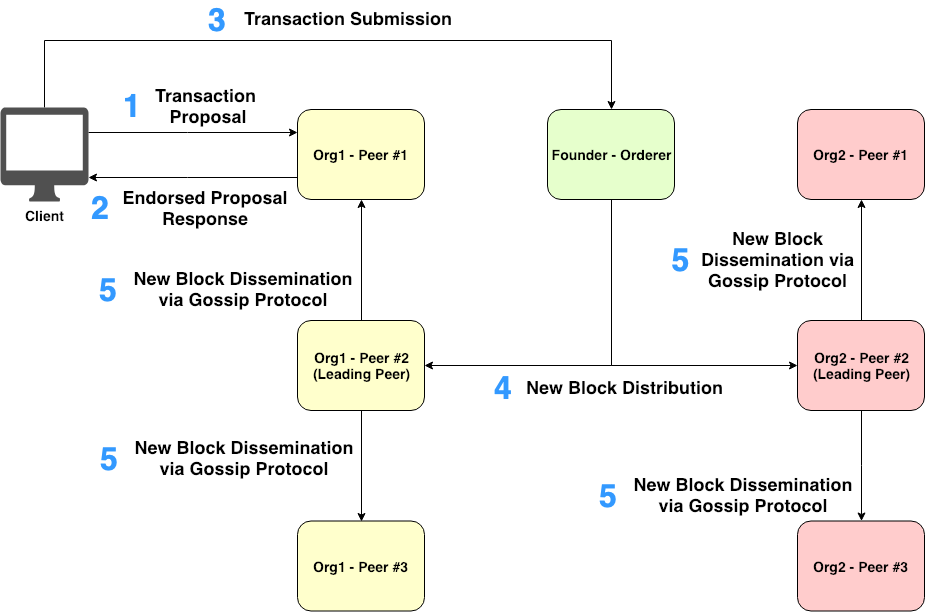
Figure 1. Fabric block dissemination scheme using Leading Peers
The step-by-step workflow of Fabric block dissemination scheme using Leading Peers is described in Figure 1:
-
Client sends a transaction proposal to the chosen Endorsing Peer(s).
-
Each Endorsing Peer generates a transaction response and sends the endorsed response back to Client.
-
Client submits the transaction attached with the endorsed response(s) to Orderer.
-
Orderer creates a block of ordered transactions and in turn distributes the created block to each of Leading Peers associated with organizations.
-
Each Leading Peer disseminates the received block to other Peers belonging to the same organization through the gossip data dissemination protocol.
The previously discussed Fabric block dissemination scheme can reduce the Orderer’s overhead significantly. Therefore, this scheme is necessary for Hyperledger Fabric. Each organization can statically define which peers to be Leading Peers. In case there is no peer statically specified, however, Fabric system also has a dynamic leading peer selection algorithm which would function automatically.
Service Discovery
In order to invoke a transaction to change the ledger’s state, a client application has to know a set of Endorsing Peers required to endorse a transaction proposal. Prior to Fabric version 1.2, this information was statically encoded into Fabric system chaincodes of a particular channel.
However, this static configuration is not resilient to network changes. For instance, when a new organization joins a channel or when a chaincode endorsement policy is changed. Moreover, the static configuration is also inflexible in case there are Endorsing Peers temporarily offline.
In Fabric version 1.2, the discovery service was introduced to facilitate a client application to discover membership and endorsement configurations, all active peers, and other available services. Refer to this link to find out the capabilities of the discovery service. The discovery service provides an API interface in terms of Fabric SDK for a client to query for information needed (e.g., listing all active peers on a channel) to the peers belonging to the same organization. The queried peers, in turn, compute the needed information dynamically and return the consumable information to the client.
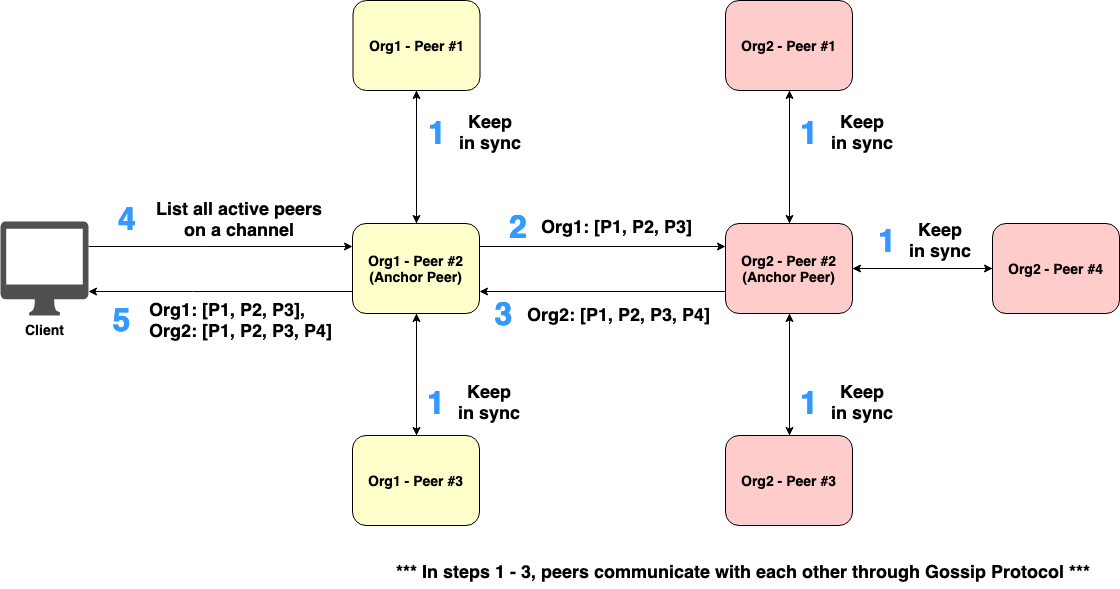
Figure 2. Peer discovery with the support of Anchor Peers
In order for the discovery service to work efficiently, the special type of Fabric peer called Anchor Peer must be configured for each organization. One of the main roles of Anchor Peer is peer discovery. More specifically, all Peers can query Anchor Peers belonging to the same organization to dynamically discover all other Peers belonging to other organizations on a channel. To prevent a single point of failure, an organization can have multiple Anchor Peers. As illustrated in Figure 2, Org1’s Peer no. 2 and Org2’s Peer no. 2 are configured to be Anchor Peers.
The step-by-step workflow of peer discovery with the support of Anchor Peers is explained in Figure 2:
-
Ordinary Peers keep periodically in sync with Anchor Peer(s) belonging to the same organization via the gossip protocol.
-
Org1’s Anchor Peer(s) periodically updates a list of Org1’s active peers to Org2’s Anchor Peer(s) using the gossip protocol.
-
Org2’s Anchor Peer(s) also periodically updates a list of Org2’s active peers to Org1’s Anchor Peer(s) through the gossip protocol.
-
Once Client needs to know a list of all active peers on the channel, Client makes a query request using Fabric SDK and sends the request to one of the Peers belonging to the same organization.
-
Queried Peer responds to Client the list of all active peers.
Operations Service
In the release of version 1.4, Hyperledger Fabric mainly focused on maturing its stability and production operations. Operations service was one of the major updates. The operations service can help system operators determine the liveness and health of Orderer Nodes, Peers, and Fabric CAs. This service also helps the operators better understand how the Fabric system is performed over time.
Each node (including Orderer Nodes, Peers, and Fabric CAs) provides the operations service by exposing the HTTP RESTful API to the system operators. To restrict access to any sensitive information, the API is isolated from Fabric blockchain services and this API is intended to be used for operating and monitoring the health of Fabric system components by the operators only.
The API exposes the following capabilities:
In this section, I would like to focus on operational metrics. Hyperledger Fabric provides two models for exposing operational metrics, that is, the pull model based on Prometheus and the push model based on StatsD.
Operational Metrics: Pull Model Based On Prometheus
We can set up Prometheus to periodically scrape operational metrics from nodes, including Orderer Nodes, Peers, and Fabric CAs, by connecting to the /metrics API endpoint that is exposed by the instrumented target nodes. Prometheus typically equips with WebUI for metrics visualization as well as alert and notification services.
To enable Fabric nodes to support Prometheus, please check out this document. Here is a list of metrics currently exported for consumption by Prometheus.
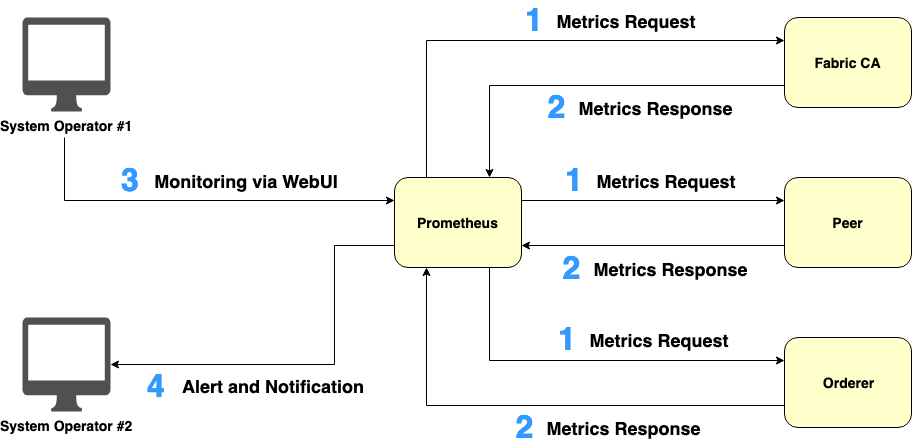
Figure 3. Utilizing Prometheus to pull operational metrics from nodes
The step-by-step workflow of utilizing Prometheus to pull operational metrics from different kinds of nodes is described in Figure 3:
-
Prometheus periodically makes pull requests for scraping metrics to Fabric target nodes.
-
Each Fabric target node responds its relevant metrics to Prometheus.
-
System operators monitor the aggregated metrics through Prometheus' WebUI.
-
Prometheus sends alerts and notifications to system operators based on conditions set by the operators.
Operational Metrics: Push Model Based On StatsD
Besides utilizing Prometheus as an engine for pulling operational metrics, Hyperledger Fabric also supports a push model based on StatsD. We can configure Fabric nodes (including Orderer Nodes, Peers, and Fabric CAs) to periodically submit operational metrics to StatsD daemon. The metrics aggregated by StatsD can then be pushed to one or more pluggable backend services such as Graphite for metrics visualization and alerting.
To configure Fabric nodes to submit metrics to StatsD, follow this document. Here is a list of metrics currently emitted for consumption by StatsD.
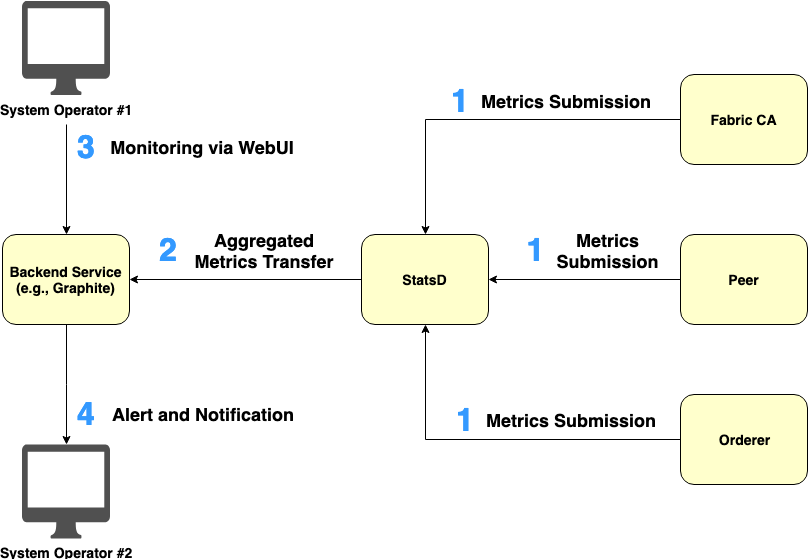
Figure 4. Pushing operational metrics from nodes to StatsD
The step-by-step workflow of pushing operational metrics from different kinds of nodes to StatsD can be illustrated in Figure 4:
-
Each Fabric node periodically submits its related metrics to StatsD.
-
StatsD submits the aggregated metrics to Backend Service such as Graphite for metrics visualization and alerting.
-
System operators monitor the aggregated metrics via Backend Service’s WebUI.
-
Backend Service sends alerts and notifications to system operators based on conditions set by the operators.
Powering Down The Series
This is the final article of Demystifying Hyperledger Fabric series. You have learned several supplementary services in Hyperledger Fabric that facilitate blockchain developers, blockchain architects, and system operators.
Actually, there are several interesting topics left to discuss in this series of articles including:
-
Multi-Version Concurrency Control in Hyperledger Fabric
-
Identity, Authentication, and Authorization in Hyperledger Fabric
-
Channel-Level Access Control and Policies
-
Advanced Chaincode Development
-
Chaincode-Level Attribute-Based Access Control
-
Chaincode-Level Encryption
-
Fabric Ordering Service in Action
-
Zero-Knowledge Proof in Hyperledger Fabric
-
Advanced Fabric Performance Optimization and High Availability
Hope one day I will have a chance to write articles regarding those topics. If you have any questions or suggestions, do not hesitate to leave your valuable comments. Until next time :)
This series of articles is organized as follows:
-
Demystifying Hyperledger Fabric (1 / 3): Fabric Architecture
-
Demystifying Hyperledger Fabric (2 / 3): Private Data Collection