Demystifying Hyperledger Fabric (1/3): Fabric Architecture

When it comes to the private blockchain, Hyperledger Fabric might be one of the most popular and adopted blockchain frameworks. Hyperledger Fabric has been adopted in several industry use cases such as education, healthcare, IoT, logistics, supply chain, and etc. Recently, NASA has published a proposal for air traffic management blockchain for security, authentication, and privacy based on Hyperledger Fabric.
In order to support massive adoptions in the future, Hyperledger Fabric has just launched the new version 1.4 which is its first long-term support release. This version mainly focuses on stability and production operations. With its popularity and key features, it is undeniable that Hyperledger Fabric is getting appealed to many software developers, software architects, system engineers, and etc.
Nonetheless, when I was learning Hyperledger Fabric for the very first time, I found that it was difficult to understand how Hyperledger Fabric really works because of its enormous technology stack. To really understand how it works, a learner is required to have knowledge of several aspects such as blockchain technology, network and system architecture, DevOps operations, full-stack software development, test driven and behavior driven development, intermediate-level cryptography, authorization and access control, IT security aspects, business use cases, and etc.
For this reason, I decided to write this article series for Hyperledger Fabric beginners. It might be easier to learn how to design and develop Hyperledger Fabric networks and applications if you already understand Fabric’s underlying architecture. Hence, this series of articles would not get into programming stuff but focus on making a reader understand Hyperledger Fabric architecture. Hope you find my articles useful. Enjoy reading :)
The remaining of this article is organized as follows:
Hyperledger Fabric Architecture
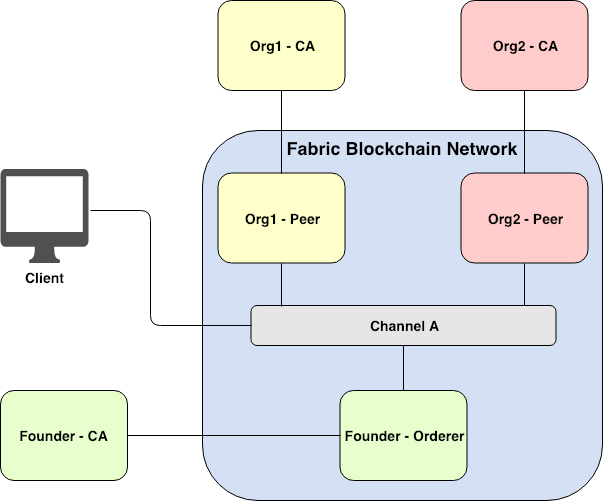
Figure 1. Simplest Fabric network with two organizations joining the same channel
In Hyperledger Fabric, there is a concept of channels which allows participating organizations to join and communicate with one another. Channel might be considered as a tunnel for one organization to secretly communicate with other participating organizations joining the same channel. Any others who do not take part in the channel in question do not ever have access to any transaction or information associated with that channel. One organization can take part in multiple channels at the same time. Figure 1 above depicts the simplest Hyperledger Fabric network with two organizations (i.e., Org1 and Org2) joining the same channel. Let me briefly introduce Fabric components one by one including Peer, Orderer, CA, and Client.
First, Peer is a blockchain node that stores all transactions on a joining channel. Each peer can join one or more channels as required. However, the storage for different channels on the same peer would be separate. Therefore, an organization can ensure that confidential information would be shared to only permitted participants on a certain channel.
Second, Orderer is one of the most important components used in the Fabric consensus mechanism. Orderer is a service responsible for ordering transactions, creating a new block of ordered transactions, and distributing a newly created block to all peers on a relevant channel. More about Orderer will be explained later on.
Third, Certificate Authority or CA is responsible for managing user certificates such as user registration, user enrollment, user revocation, and etc. More specifically, Hyperledger Fabric is a permissioned blockchain network. This means that only permitted users can query (access to information) or invoke (create a new transaction) a transaction on a granted channel. Hyperledger Fabric uses an X.509 standard certificate to represent permissions, roles, and attributes to each user. In other words, a user is able to query or invoke any transaction on any channel based on permissions, roles, and attributes he/she possesses.
Fourth, Client is considered to be an application that interacts with Fabric blockchain network. That is, Client can interact with Fabric network according to its permissions, roles, and attributes as specified on its certificate derived from its associated organization’s CA server.
Notice that each component was painted a different color to distinguish a different organization. The components inside the big blue box are on-chain Fabric network entities whereas the components outside the blue box are considered to be off-chain entities.
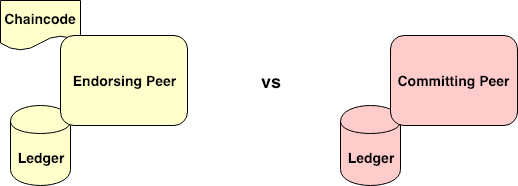
Figure 2. Endorsing Peer vs Committing Peer
There is a concept of Smart Contract called Chaincode in Fabric. Currently, three languages can program Fabric chaincode including Golang, Node.js, and Java. To deploy a chaincode, a network admin must install the chaincode onto target peers and then invoke an orderer to instantiate the chaincode onto a specific channel. While instantiating the chaincode, an admin can define an endorsement policy to the chaincode. Endorsement policy defines which peers need to agree on the results of a transaction before the transaction can be added onto ledgers of all peers on the channel.
A peer specified in the endorsement policy is called an endorsing peer which consists of an installed chaincode and a local ledger on it whereas a committing peer would have only a local ledger on it. Figure 2 distinguishes between an endorsing peer and a committing peer. More on this will be discussed when we reach Fabric consensus section.
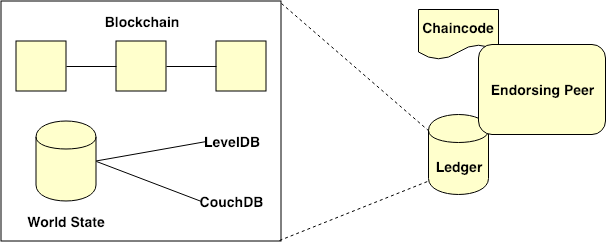
Figure 3. Interior components inside the Peer’s ledger
As illustrated in Figure 3, the interior components inside the Peer’s ledger include Blockchain and World State. Blockchain holds the history of all transactions for every chaincode on a particular channel. World State maintains the current state of variables for each specific chaincode.
Two types of World State database currently supported in Fabric include LevelDB and CouchDB. LevelDB is a default key-value database built on Fabric Peer, whereas CouchDB is a JSON-based database supporting rich querying operations based on JSON objects. For instance, CouchDB allows us to set an asset with a specific key and query filtered assets using JSON querying syntax. A chaincode developer must opt to use either LevelDB or CouchDB when developing a chaincode.
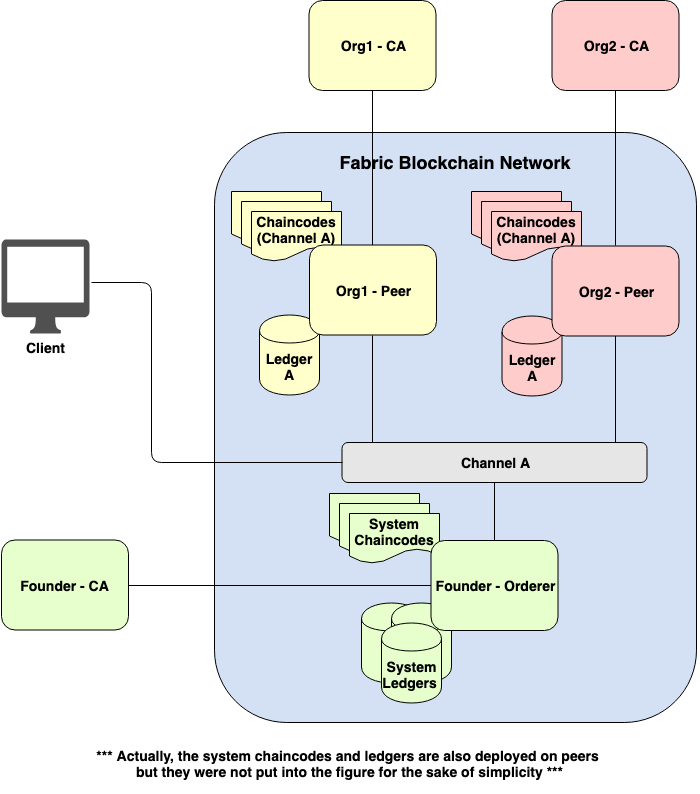
Figure 4. Fabric network with chaincodes and ledgers attached
The previous Fabric network can be decorated with chaincodes and ledgers as shown in Figure 4. As you can see, Org1’s Peer and Org2’s Peer mutually join the same channel. There can be multiple chaincodes instantiated on the same channel. Furthermore, the instantiated chaincode can be upgraded if needed. This makes a chaincode to be updatable or patchable.
Let’s pay attention to Orderer. There are special system chaincodes and ledgers for Orderer. System chaincodes collect network, channel, and underlying system configurations for Fabric virtual machine to work properly; they are opposed to user chaincodes which run in separate docker containers.
In fact, system chaincodes are also registered and deployed on peers at bootstrap but they were not put into Figure 4 for the sake of simplicity. System chaincodes include but are not limited to:
-
QSCC (Query System Chaincode) for ledger and Fabric-related queries
-
CSCC (Configuration System Chaincode) which helps regulate access control
-
LSCC (Lifecycle System Chaincode) which defines the rules for the channel
-
ESCC (Endorsement System Chaincode) for endorsing transactions
-
VSCC (Validation System Chaincode) for validating transactions
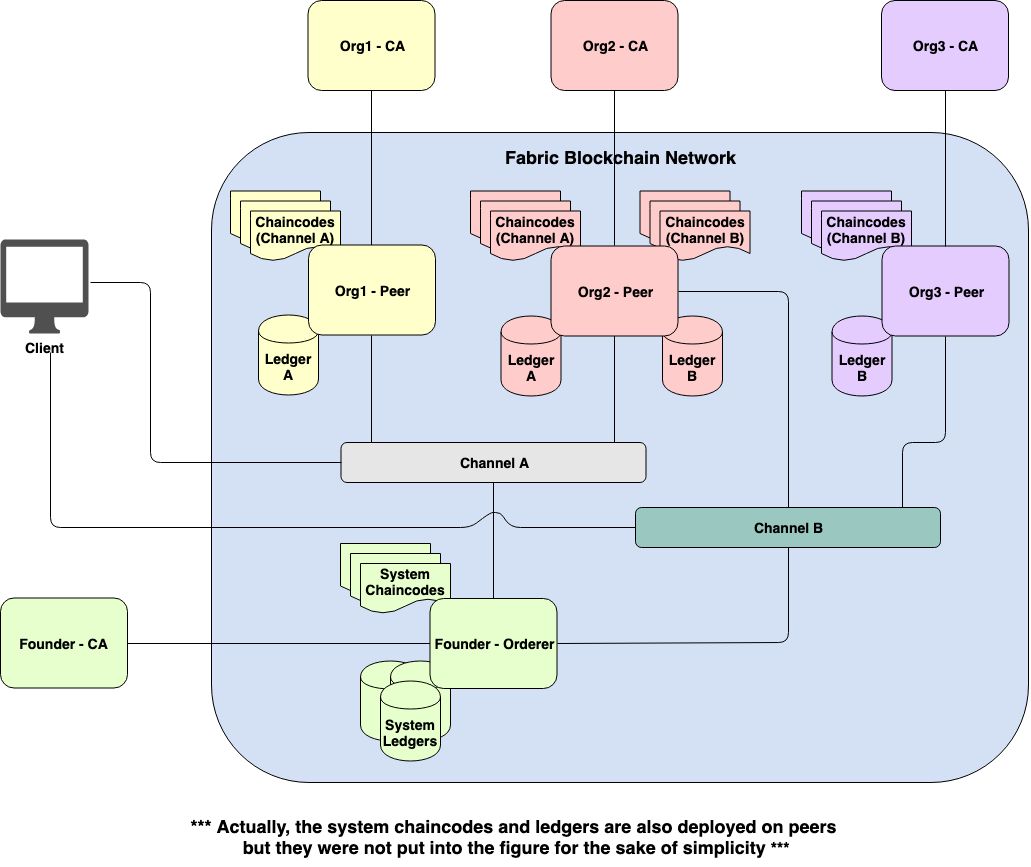
Figure 5. More complex Fabric network with multiple channels
Figure 5 illustrates a more complex Fabric network with multiple channels. Org1’s Peer and Org2’s Peer join Channel A together, while Org2’s Peer and Org3’s Peer mutually join Channel B. With a separate channel, organizations that join the same channel can secretly share business transaction or information together with confidence.
In addition, one chaincode can call another chaincode on the same channel. Moreover, a chaincode can also call another chaincode on a different channel in case a calling chaincode is executed on an endorsing peer joining those two related channels like what Org2’s Peer is doing.
The Consensus in Hyperledger Fabric
Fabric consensus has an abundance of multi-stage and multi-hierarchy of endorsement, validity, and versioning checks. There are multiple phases to ensure the permission, endorsement, data synchronization across all participants, transaction order, and correctness of changes before writing a block of transactions onto the ledger.
Hyperledger Fabric uses a permissioned voting-based consensus which assumes that all participants in the network are partially trusted. The consensus can be divided into three phases as follow.
-
Endorsement (Steps 1–3 in Figure 6 below)
-
Ordering (Steps 4–5 in Figure 6 below)
-
Validation and Commitment (Step 6 in Figure 6 below)
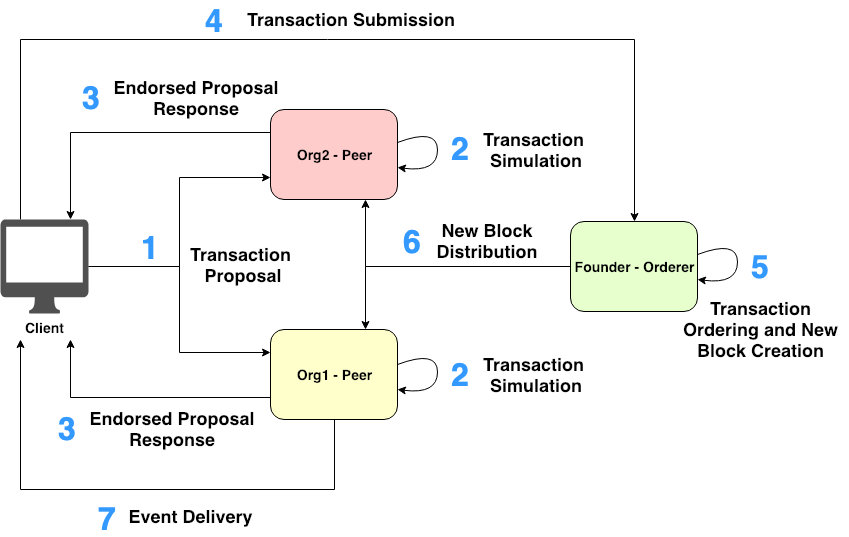
Figure 6. Fabric transaction invocation workflow
Figure 6 describes the step-by-step workflow of Fabric transaction invocation:
-
Client makes a transaction proposal, signs the proposal with User’s certificate, and sends the transaction proposal to a set of pre-determined Endorsing Peers on a specific channel.
-
Each Endorsing Peer verifies User’s identity and authorization from the proposal payload. If the verification check passes, Endorsing Peer simulates the transaction, generates a response together with a read-write set, and endorses the generated response using its certificate.
-
Client accumulates and checks the endorsed proposal responses from Endorsing Peers.
-
Client sends the transaction attached with the endorsed proposal responses out to Orderer.
-
Orderer orders the received transactions, generates a new block of ordered transactions, and signs the generated block with its certificate.
-
Orderer broadcasts the generated block to all Peers (to both Endorsing Peers and Committing Peers) on the relevant channel. Then, each Peer ensures that each transaction in the received block was signed by the appropriate Endorsing Peers (i.e., determining from the invoked chaincode’s endorsement policy) and enough endorsements are present. After that, a versioning check (called the multi-version concurrency control (MVCC) check) will take place to validate the correctness of each transaction in the received block. That is, each Peer will compare each transaction’s readset with its ledger’s world state. If the verification check passes, the transaction is marked as valid and each Peer’s world state is updated. Otherwise, the transaction is marked as invalid without updating the world state. Finally, the received block is appended into each Peer’s local blockchain regardless of whether or not the block contains any invalid transactions.
-
Client receives any subscribed events from EventHub service.
Ordering Service in Hyperledger Fabric
Update:
At the time of writing this article, Hyperledger Fabric (v1.4.1) has just silently launched its new ordering service based on Raft protocol. Intriguingly, Raft-based ordering service allows different organizations to contribute nodes to a distributed ordering service. I will write an article regarding this interesting ordering service if I have a chance.
Orderer might be one of the most important components in Hyperledger Fabric. It acts as a hub for distributing blocks of transactions to all peers on a relevant channel. For this reason, Orderer might be considered to be the weakest point in the Fabric network.
The current implementation of Fabric Orderer supports two types of ordering service, namely Solo and Kafka. Solo-based ordering service is recommended for use in the development environment only since this kind of service composes of a single process which serves all clients. This is prone to be a single point of failure in a production environment.
In production, Kafka-based ordering service is intended to be used. With Kafka, we can set up a Kafka cluster and a ZooKeeper ensemble to provide a crash fault-tolerant ordering service.
Even though Kafka would provide Crash Fault Tolerance (CFT) consensus to Orderer, there can still be only one organization to fully control the ordering service. It is, however, insufficient for one organization to mastermind Orderer because that organization may not be trustworthy.
Fortunately, Fabric ordering service was designed to be pluggable. Currently, Byzantine Fault Tolerant (BFT) consensus is under development. The BFT-based consensus would enable the network’s participating organizations to jointly control the ordering service, resisting the system from reaching agreement in the case of malicious actors or faulty nodes.
Hyperledger Fabric in Production
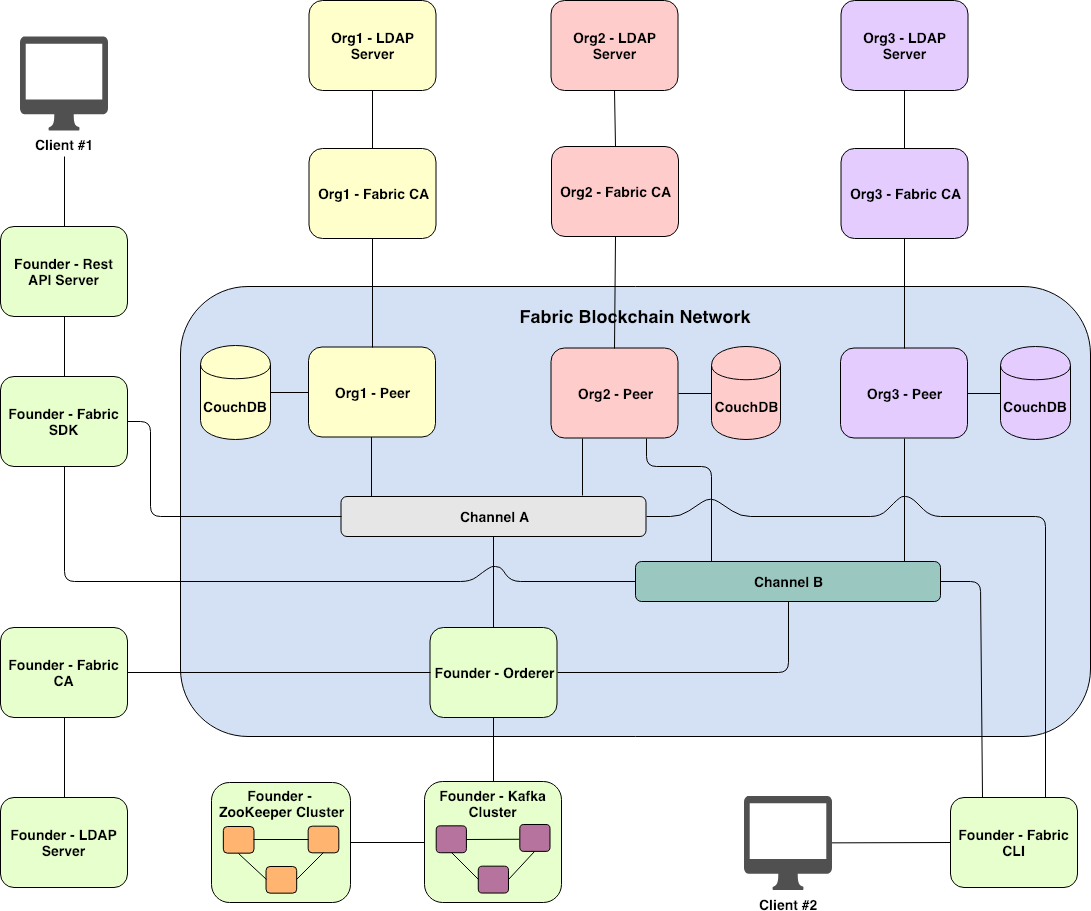
Figure 7. Fabric network in a production environment
In production, there can still be several Fabric-related components to be collaborating with. Figure 7 summarizes a deployment model for Fabric network in a production environment.
Client application can interact with Fabric blockchain network in two ways: via Fabric SDK or Fabric CLI (command line interface). Fabric SDK provides a set of rich functions, which is appropriate for use in production. Typically, Client application (Client no. 1 in Figure 7) interacts with Fabric network by way of connecting to RESTful API Server which uses Fabric SDK as a library to communicate with the blockchain network. Fabric SDK currently supports Node.js and Java languages. In addition, Python, Golang, and REST SDK versions are under development. Fabric CLI is appropriate for use in a development or maintenance mode (Client no. 2 in Figure 7).
In Fabric, CA is used for user management and certificate issuance tasks. There are two ways to deploy Fabric CA. First, setting up Fabric CA without extending LDAP Server. With this configuration, Fabric CA would be used for registering users, authenticating users, and issuing user certificates (i.e., user enrollment). Second, setting up Fabric CA with extending LDAP Server. With this configuration, Fabric CA would be used for issuing user certificates only. Whereas, Fabric CA would delegate LDAP Server to manage other tasks instead such as registering users, authenticating users, revoking users, and etc. The second option is suitable for connecting Fabric CA with an organization’s existing AD, LDAP or Radius server.
CouchDB might be the best option to use as a world state database for Peer’s ledger in production since it supports several rich features, such as JSON querying operations, database indexing, data replication, ACID properties, and etc. Whereas, LevelDB supports only limited operations.
To support Crash Fault Tolerance (CFT) consensus for Fabric ordering service, extending Orderer with a cluster of Kafka brokers is a choice in production. In order for Kafka cluster to work properly, a ZooKeeper cluster is required for coordinating local tasks across distributed Kafka brokers.
Summary
In this article, you have learned Hyperledger Fabric’s architecture, how Fabric consensus and ordering service work, and how to deploy Fabric network in a production environment. Hope you enjoy my contents and learn something new.
In the next article, you will learn Private Data Collection which is another key feature of Hyperledger Fabric. See you again.
This series of articles is organized as follows:
-
Demystifying Hyperledger Fabric (1 / 3): Fabric Architecture
-
Demystifying Hyperledger Fabric (2 / 3): Private Data Collection